
Die 4 Säulen der semantischen Suche und warum sie für SEO wichtig sind
Mit einer semantischen Suche finden Suchmaschinen Inhalte nicht mehr nur nach Keywords, sondern aufgrund der inhaltlichen Bedeutung. In diesem Blog-Beitrag gebe ich dir einen Überblick über die 4 wichtigsten Säulen der semantischen Suche, die du für die Suchmaschinenoptimierung kennen solltest. Diesen Text habe ich als Überblick und für Verständlichkeit geschrieben. Daher ist einiges abstrahiert.
- Relevantere Suchergebnisse mit semantischer Suche
- Die 4 Säulen der semantischen Suche
- Weitere Anwendungsfälle der 4 Säulen der semantischen Suche
- Zusammenfassung: Worauf es bei der semantischen Suche ankommt
Relevantere Suchergebnisse mit semantischer Suche
Durch die semantische Suche kann eine Suchmaschine sowohl die indexierten Seiten als auch die Suchanfrage inhaltlich (semantisch) verstehen. Dadurch kann eine Suchmaschine relevantere Inhalte in den SERPs anzeigen. Außerdem ist eine semantische Suche nicht so anfällig für Manipulation wie eine rein auf Keywords basierende ("lexikalische") Suche.
Klassische lexikalische Ranking-Algorithmen waren etwa TF-IDF oder BM25, die in den 80er und 90er Jahren entwickelt wurden. Selbst wenn man bei diesen Ranking-Algorithmen zusätzliche Signale wie Links von anderen Websites berücksichtigt, haben sie 2 große Probleme:
Sie sind anfällig für Manipulation. Etwa für Keyword-Stuffing, aufgeblähten Text oder gekaufte Links. Das galt insbesondere für TF-IDF. Deshalb versuchte der BM25-Algorithmus bereits in den 90 Jahren, den Effekt von Keyword-Stuffing und aufgeblähten Texten zu reduzieren.
Sie sind rein lexikalisch und verstehen die inhaltliche Bedeutung von Suchanfragen und Texten nicht. Wenn ich etwa als Suchanfrage "Rhyolite" eingebe, weiß eine lexikalische und Keyword basierende Suchmaschine nicht, ob ich damit die Geisterstadt in Nevada oder die gleichnamige Gesteinsart meine. "Rhyolite" ist ein Beispiel für ein "Homonym": Ein Begriff, der unterschiedliche Dinge bezeichnet.
Deshalb haben Suchmaschinen schon lange vor ChatGPT & Co damit begonnen, von lexikalischen Ranking-Algorithmen auf semantische Ranking-Algorithmen umzustellen. Die Grundlage dafür ist KI im allgemeinen und maschinelles Lernen im Speziellen.
Als Datum für den Beginn der Umstellung auf die semantische Suche sehe ich das Jahr 2012. Aus diesem Jahr stammt Googles bekannter Blog-Beitrag Things, not Strings. Der zweite Meilenstein der semantischen Suche war das Google "Hummingbird" Update im Jahr 2013. Das war laut Google das dramatischste Update seit 2001 und betraf fast 90 % der Suchanfragen.
Seitdem gab es laufend Aktualisierungen und neue Ranking-Systeme für die semantische Suche wie "Rank-Brain", "BERT" oder "MUM".
Für die Suchmaschinenoptimierung solltest du die 4 Säulen der semantischen Suche kennen.
Die 4 Säulen der semantischen Suche
Die 4 Säulen der semantischen Suche sind nicht "4 Ranking Faktoren" oder "4 Ranking-Systeme". Es sind Konzepte, die aus mehreren Ranking-Systemen und Signalen bestehen. Es sind meiner Erfahrung nach die 4 wichtigsten Säulen, die du direkt bei der Suchmaschinenoptimierung berücksichtigen kannst.
Entitäten
Im Patent US20160371385A1 definiert Google im Abschnitt [015] eine Entität als "ein Ding oder Konzept, das singulär, einzigartig, gut definiert und unterscheidbar ist". Etwas weniger akademisch formuliert definiere ich eine Entität als ein "eindeutiges Ding, dessen Bedeutung eine Suchmaschine kennt".
Aufgrund von Entitäten weiß eine semantische Suchmaschine, dass mit den Begriffen "Vienna" (englisch für Wien), "Viena" (spanisch für Wien), "Hauptstadt Österreichs", "österreichische Bundeshauptstadt" und "bevölkerungsreichste Stadt der Republik Österreich" immer das "Ding" namens "Wien" gemeint ist.
Außerdem kann eine semantische Suchmaschine aufgrund von Entitäten zwischen "Bienenstich" und "Bienenstiche" unterscheiden. In einer rein lexikalischen Suche wären die beiden Suchbegriffe nach einer sogenannten "Stammformreduktion" dasselbe Keyword. Eine semantische Suche hingegen erkennt in "Bienenstich" eine leckere Süßspeise und in "Bienenstiche" eine schmerzhafte Begegnung mit einem nützlichen Tier.
Versuche es selbst: Gib zunächst deinen einen Suchbegriff und dann den anderen ein und sieh dir die Suchergebnisse an.
Das Verständnis der Bedeutung bzw. die Fähigkeit zur inhaltlichen Unterscheidung entsteht zum Beispiel durch die Verknüpfung zweier Entitäten miteinander.
Schreibe ich in einem englischen Text den Satz "Rhyolite is a Ghost Town in Nevada" erkennt die semantische Suche, die sprachliche Verknüpfung von "Rhyolite" mit "Ghost Town" und "Nevada" und weiß damit, dass es im Text um die bekannte Geisterstadt geht und nicht um die gleichnamige Gesteinsart.
Auch Verben helfen, dass eine semantische Suchmaschine die Bedeutung einer Entität verstehen kann. Schreibe ich z.B. "I visited Rhyolite during a Roadtrip" erkennt die semantische Suchmaschine aufgrund des Verbs "visited", dass es sich bei "Rhyolite" mit hoher Wahrscheinlichkeit um die Geisterstadt handelt. Schreibe ich hingegen "I found Rhyolite during a Roadtrip" vermutet eine Suchmaschine, dass ich die gleichnamige Gesteinsart gefunden habe. Verwende ich hingegen die Formulierung "I found the Ghost Town of Rhyolite during a Roadtrip" versteht die Suchmaschine aufgrund der sprachlichen Verknüpfung von "Ghost Town" und "Rhyolite", dass es sich trotz des Verbs "found" um die Geisterstadt handelt
Für die Suchmaschinenoptimierung bedeutet das:
Nenne die Dinge beim Namen. Das ist der Name der Entität. Vermeide blumige Umschreibungen sowohl im Text als auch in Überschriften.
Verwende im Text immer wieder einmal verknüpfte Entitäten.
Achte auf die Wortwahl bei den Verben.
Die primäre Entität und somit das "Thema" eines Textes nenne ich "Conceptual Intent". Es wird manchmal auch als "Topical Intent" oder "Content Domain" bezeichnet. Mehr Informationen über Entitäten kannst du in meinem Blogpost über Entitäten und ihre Bedeutung für die Suchmaschinenoptimierung nachlesen.
Entitäten findest du nun im sogenannten "Knowledge Graph".
Der Knowledge Graph
Ein "Knowledge Graph" ist ein riesiges, sich ständig änderndes Netz von Entitäten und deren Verknüpfungen untereinander. Im Google Knowledge Graph waren laut einem Google-Artikel im Jahr 2020 mehr als 5 Milliarden Entitäten enthalten.
Nun verwendet nicht nur Google einen Knowledge Graph. Viele andere Unternehmen und Organisationen verwenden sie ebenfalls, um Daten und Informationen über "Dinge" zu speichern. So kannst du etwa den Knowledge Graph von Wikipedia unter Wikidata durchsuchen.

Beispielentität in Wikidata
Der Google Knowledge Graph wird durch Entitäten aus anderen Knowledge Graphen befüllt. Laut des originalen Blog Post "Things, not Strings" verwendet Google als Quelle das von ihnen gekaufte "Freebase", "Wikipedia" und das "CIA World Factbook, aber auch "andere lizenzierte Quellen". Auch durch maschinelles Lernen kann Google neue Entitäten und Verbindungen zwischen Entitäten in einem Text erkennen und sie dem Knowledge Graph hinzufügen.
Den Google Knowledge Graph kannst du etwa auf technicalseo.com durchsuchen.
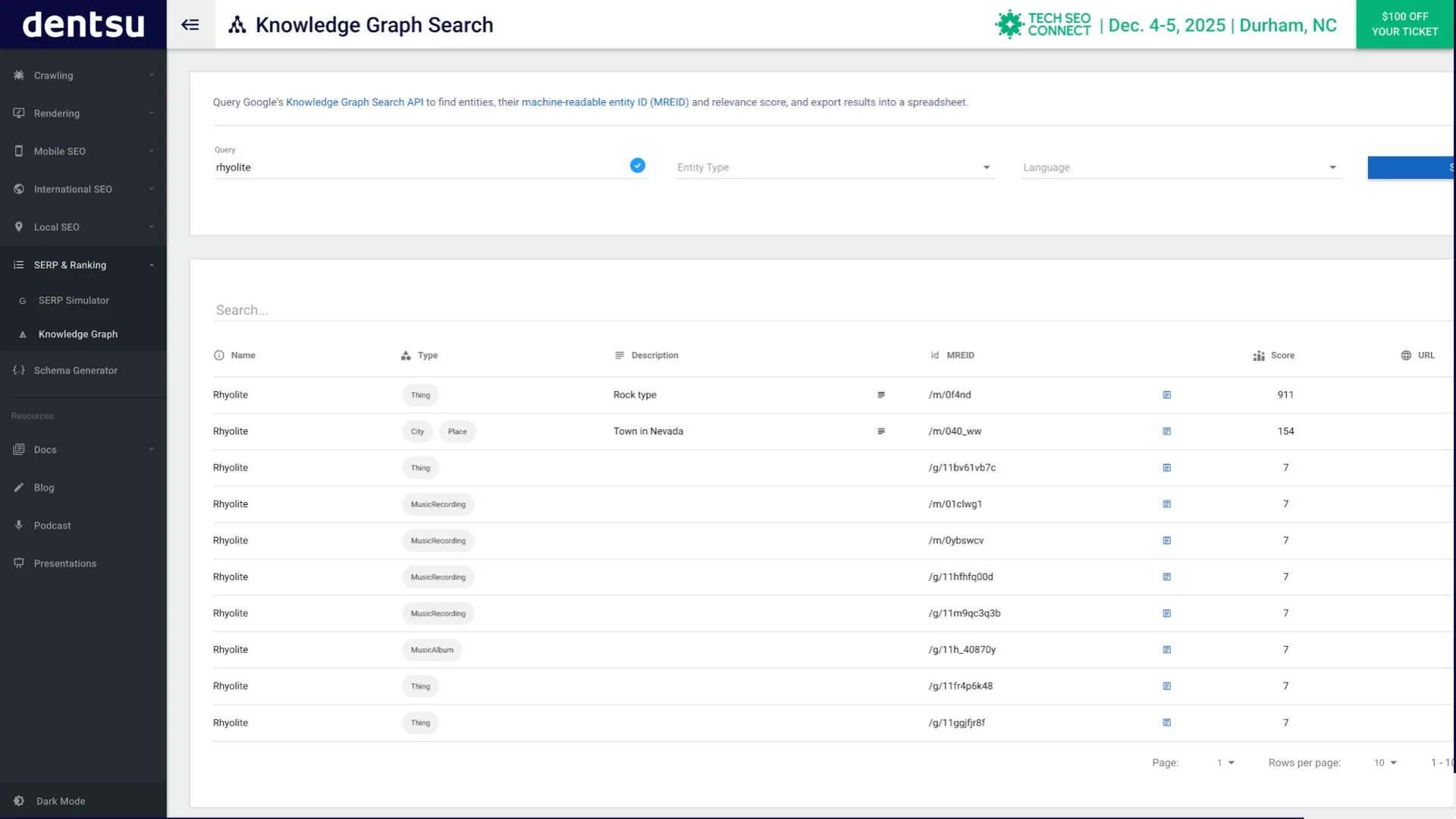
Suchergebnis für eine Suche im Google Knowledge Graph auf technicalseo.com
Der Knowledge Graph ändert sich ständig. Es kommen neue Entitäten hinzu, andere werden entfernt und die Verknüpfungen zwischen Entitäten werden neu bewertet.
Für deine Suchmaschinenoptimierung bedeutet das:
- Durchsuche den Knowledge-Graph um eine passende Entität für das Thema deines Textes zu finden. Etwa den Google Knowledge Graph auf technicalseo.com oder den Wikipedia Knowledge Graph auf Wikidata.
Eine passende Entität ist stets das "Ding", um das es sich in deinem Text dreht. Für einen Artikel über "die schönsten Fotospots in Rhyolite" ist die korrekte Entität "Rhyolite" und nicht "Foto Spots".
Sowohl Entitäten als auch der Knowledge Graph spielen nun beim "Natural Language Processing" eine wichtige Rolle.
Das Natural Language Processing
Mit dem "Natural Language Processing" (NLP) versteht eine semantische Suchmaschine, worum es inhaltlich (semantisch) in einer Suchanfrage und in einem Text geht. Sie versteht, dass bei einer Suchanfrage nach "Bienenstich" ein Rezept gemeint ist und nicht eine schmerzhafte Begegnung mit einer Biene.
Die zwei Kernaufgaben des Natural Language Processing sind:
- Die Erkennung von Entitäten (engl. "Named Entity Recognition") in einem Text
- Die erkannten Entitäten zueinander in Beziehung zu setzen.
Wenn du jetzt denkst, dass das wie ein Knowledge Graph klingt, liegst du richtig. Durch das Natural Language Processing entsteht für einen Text insgesamt und einzelne Passagen so etwas ein "kleiner Knowledge Graph".
Nehmen wir als Beispiel den Satz: "Rhyolite ist a Ghost Town in Nevada". Dieser Satz enthält 3 Entitäten, nämlich "Rhyolite", "Ghost Town" und "Nevada". Das Natural Language Processing setzt diese drei Entitäten aufgrund der Sprache in Relation zueinander und verwendet dafür sogenannte "Statements" (Aussagen). Dadurch entstehen sogenannte "Triples": Da sieht dann so aus:
- "Rhyolite" is-a: "Ghost Town"
- "Rhyolite" location: "Nevada"
Mit so einem "kleinen Knowledge Graph" (auch als "semantischer Graph" bezeichnet) kann eine Suchmaschine die Relevanz eines ganzen Textes oder einer Passage in einem Text für eine Suchanfrage ermitteln. Natürlich kommen dabei noch dutzende oder sogar hunderte andere Ranking-Signale ins Spiel, die ich einfachheitshalber außen vor lasse.
Nun wird beim Natural Language Processing jeder erkannten Entität in einem Text eine "Salienz" zugewiesen. Das ist die Relevanz einer Entität im Vergleich zu anderen Entitäten im Text. Achte hier bitte auf meine Wortwahl: "Relevanz im Vergleich zu anderen Entitäten". Das heißt nicht, dass eine bestimmte Entität die höchste Relevanz hat, weil sie mit einer Häufigkeit von 2% im Text vorkommt. Die Relevanz ergibt sich auch daraus, wo die Entität im Text und in einem Satz vorkommt; etwa im Hauptsatz oder im Nebensatz.
Für die Suchmaschinenoptimierung bedeutet das:
- Achte auf deinen Schreibstil und verwende Entitäten möglichst oft (aber nicht immer) im Hauptsatz. Verwende statt Formulierungen wie "Eine der schönsten Geisterstädte, die ich jemals besucht habe, ist Rhyolite" den Satz "Rhyolite ist eine der schönsten Geisterstädte, die ich jemals besucht habe".
- Verwende die Entität in passenden Überschriften. Vermeide Teaser- oder Clickbait-Überschriften. Eine Überschrift ist eine Zusammenfassung des Textes oder eines Absatzes in einem Satz.
Vektoreinbettungen
Mithilfe von "Vektoreinbettungen" wird die inhaltliche Bedeutung eines Textes (also alle Wörter, Entitäten und deren Beziehungen zueinander) in einen mathematischen Vektor umgewandelt. Hier kommt nun das zu tragen, was ich weiter vorn erwähnt habe. Mit dem Natural Language Processing werden nicht nur bekannte Entitäten extrahiert, sondern auch alles anderen "Dinge" wie z.B. "Foto Spots".
Nun ist "Foto Spots" keine Entität im Knowledge Graph. Aber sie wird durch maschinelles Lernen als eigener Vektor in der Nähe von ähnlichen (und bekannten) Entitäten gespeichert; z.B. in der Nähe des Vektors "Fotografieren".
Dasselbe macht eine semantische Suchmaschine mit einer Suchanfrage. Sie wird durch das Natural Language Processing verarbeitet und dann in eine Vektoreinbettung umgewandelt.
Für die Relevanz eines Textes vergleicht eine Suchmaschine, wie nahe der Vektor einer Suchanfrage einem Vektor eines Textes ist.
Für die Suchmaschinenoptimierung bedeutet das:
- Schreibe fokussiert über ein Thema wie "Fotospots in Rhyolite". Vermeide, den Text mit "SEO Blah" künstlich aufzublasen, nur um eine bestimmte Textlänge zu erreichen. Das kann die Vektoreinbettung für deinen Text negativ beeinflussen.
Schreibe ich einen Text über "Fotospots in Rhyolite" geht es ausschließlich darum. Ewig lange und für das Thema irrelevante "SEO-Blah" Absätze wie über die Geschichte der Geisterstadt vermeide ich.
Weitere Anwendungsfälle der 4 Säulen der semantischen Suche
Die oben erwähnten 4 Säulen werden in einer semantischen Suche einerseits für eine Relevanzbewertung von Texten in Relation zur Suchanfrage verwendet. Es gibt aber noch weitere Anwendunfälle in der semantischen Suche:
- Mit einer Sentiment-Analyse wird ermittelt, ob ein Text eher positiv, eher neutral oder eher negativ geschrieben ist
- Zur Erkennung von SPAM, in dem Texte auf typische SPAM-Muster geprüft werden. Dafür hat Google genügend Trainingsdaten.
- Zur weitgehend sprachunabhängigen Relevanzbewertung, da nicht die Wörter (Keywords) sondern deren Bedeutung berücksichtigt wird.
- Um die "thematische Autorität" für das Ranking zu bewerten. Schreibe ich über "Foto Spots in Rhyolite", erwartet eine KI z.B. die Erwähnung der wichtigsten Gebäude. Das sind wiederum mit "Rhyolite" verknüpfte Entitäten.
- Antworten auf Fragen zu liefern. Dazu musst du die Frage nicht als Keyword im Text wiederholen, sondern einfach die Antwort schreiben.
Zusammenfassung: Worauf es bei der semantischen Suche ankommt
Die semantische Suche funktioniert nicht darüber, wie oft ein Wort in einem Text vorkommt. Sie berücksichtigt die inhaltliche (semantische) Bedeutung der Wörter. Damit also eine Maschine deinen Text als relevant bewerten kann, sind meiner Erfahrung nach die drei wichtigsten Tipps:
- Schreibe einfach und verständlich. Vermeide eine zu blumige oder bildhafte Sprache.
- Nenne Dinge beim Namen (Entität!) anstatt sie zu umschreiben. Schreibe über "Rhyolite" statt über die "schönste Geisterstadt in Nevada".
- Schreibe hyperfokussiert auf ein Thema, schweife nicht ab und vermeide irrelevantes "SEO-Blah".