
Wie funktioniert eine Suchmaschine. Einfach erklärt
Die allgemeine Funktion einer Suchmaschine ist kein Geheimnis. Jede Seite muss mehrere Schritte durchlaufen, bevor sie in den Suchergebnissen angezeigt werden kann.
In diesem Blog-Beitrag liest du einen High-Level-Überblick darüber, wie eine Suchmaschine heute funktioniert, welche Schritte jede einzelne Seite durchlaufen kann und du erfährst wichtige Punkte, auf die du in jedem einzelnen Schritt achten solltest
- Website bei Suchmaschinen anmelden
- Die 4 Schritte einer Suchmaschine
- Die Suche verwendet schon seit langem KI
- Zusammenfassung
Website bei Suchmaschinen anmelden
Damit eine Suchmaschine deine Seiten überhaupt in den Ergebnissen anzeigen kann, muss sie von der Existenz deiner Website wissen.
In den guten alten SEO-Zeiten vor dem Jahr 2000 gab es dazu einfach ein Textfeld bei den Suchmaschinen. Dort hast du die Startseite deiner Website eingetragen. Dann hat es ein paar Wochen gedauert, bis deine Seiten in den Index aufgenommen wurden.
Heute gibt es zwei Möglichkeiten, um einer Suchmaschine mitzuteilen, dass deine Website existiert:
Eine bereits indexierte Website setzt einen Link auf deine Website. Das ist der aufwendige und langsame Weg.
Du meldest deine Website selbst bei den Suchmaschinen an. Dazu bieten viele Suchmaschinen sogenannte “Webmaster-Tools“
Solche Webmaster-Tools zum Anmelden deiner Website findest du bei diesen Suchmaschinen:
Für Google mit der Google Search Console.
Für Bing mit den Bing Webmaster Tools
Für Yandex mit den Yandex Webmaster Tools
Für Baidu mit den Baidu Webmaster Tools. Dafür solltest du allerdings Chinesisch können und im Besitz einer chinesischen Telefonnummer sein. Registriere dich zunächst für einen Baidu Passport und wechsle dann in das Webmaster-Dashboard, um deine Website anzumelden.
Auch für die lokale Suche bieten manche Suchmaschinen etwas Ähnliches wie die Webmaster-Tools:
Google My Business für Google Maps
MapsConnect für Apple Maps
Bing Places for Business für die Karten in Bing
In dieser Liste fehlen einige Suchmaschinen aus gutem Grund, zum Beispiel Yahoo oder DuckDuckGo. Diese bieten keine eigenen Webmaster-Tools an, da Sie den Index von anderen Suchmaschinen verwenden. So ist Yahoo im Wesentlichen eine "rebranded" Version von Bing, und DuckDuckGo nutzt laut eigenen Angaben über 400 spezialisierte Quellen, um Suchergebnisse anzuzeigen.
Auf StatCounter.com findest du eine Übersicht der Marktanteile jeder Suchmaschine, die du nach Ländern filtern kannst. Das hilft dir herauszufinden, bei welchen Suchmaschinen du deine Website zusätzlich zu Google anmelden solltest.
Falls du es bisher nicht gemacht hast, melde nun deine Website mit den Webmaster Tools bei den Suchmaschinen an. Für die Google Search Console findest du in meinem Blog eine Anleitung, um die Google Search Console einzurichten. Das Einrichten ist auch Teil meines Search Console Kurses auf Udemy.
Die 4 Schritte einer Suchmaschine
Google verwendet in seiner Dokumentation nur 3 Phasen zur Beschreibung der Funktion einer Suchmaschine. Sie haben die beiden Phasen "Ranking" und "Serving" in einer Phase zusammengefasst.
Crawling
Nachdem du deine Website bei einer Suchmaschine angemeldet hast, wird deine Website von einem “Bot” gecrawlt. Der Bot lädt dabei drei Arten von Dateien von deiner Website:
Dateien zur Crawl-Steuerung wie die robots.txt-Datei und die Sitemap-Datei.
Indexierbare Dateien wie HTML-Seiten, aber auch PDF-Dateien oder Word-Dokumente. In der Google-Hilfe findest du eine Liste der von Google indexierbaren Dateitypen.
Ressourcen, die für das Rendering von HTML-Seiten benötigt werden (dazu gleich mehr).
Nun durchsucht die Suchmaschine die heruntergeladenen Dateien nach Links zu weiteren indexierbaren Dateien und crawlt diese. Das ist der Hauptzweck des Crawlings: Indexierbare Dateien zu finden.
Für HTML-Dateien gibt es noch einen zusätzlichen Schritt. Nachdem die Suchmaschine eine HTML-Datei und alle dafür notwendigen Ressourcen wie Bilder, JavaScript und CSS geladen hat, wird die Seite “gerendert”. Dazu wird das JavaScript auf der Seite ausgeführt, das auch ein Browser nach dem Laden einer Seite ohne Nutzerinteraktion ausführen würde.
Durch das Rendern entsteht ein HTML-Quelltext einer Seite, der auch durch JavaScript eingefügte Inhalte und Links enthält.
Jetzt durchsucht der Bot den HTML-Quelltext der gerenderten Seite noch einmal nach Links zu weiteren Seiten und indexierbaren Dateien.
Suchmaschinen wie Google crawlen deine Seiten mit unterschiedlichen Bots: einmal für den Desktop und einmal für Mobile. In der Google Search Console siehst du sowohl den primären Spider als auch den Spider, mit dem jede einzelne Seite (unter Umständen nochmals) gecrawlt wurde. Für Google siehst du das in der Google Search Console unter “Einstellungen” und “Crawling Statistiken”.

Google Bottypen in der Google Search Console
Rechts unten siehst du die verschiedenen Bottypen, mit denen Google meine Seite crawlt. Für die Indexierung verwendet Google allerdings nur mehr den Smartphone-Bot (“Mobile Indexing”).
Das Crawl-Budget
Ein Suchmaschinenbot besucht deine Website regelmäßig. Dabei crawlt er einen Teil der Seiten deiner Website. Das "Crawl-Budget" ist die Anzahl der URLs, die der Bot beim Besuch deiner Website im Durchschnitt crawlt.
Suchmaschinenbots haben in der Regel eine Logik, nach der sie URLs für das Crawling auswählen. Dazu gehört etwa:
Wann wurde die URL zuletzt gecrawlt?
Wie oft hat sich in der Vergangenheit der Inhalt der URL geändert?
Ist die URL in der Sitemap vorhanden?
Wie "tief" ist die URL ausgehend von der Startseite verlinkt?
Wie schnell werden die Seiten ausgeliefert?
Der "Page Speed" ist ein wichtiger Aspekt für das Crawling. Aber nicht, weil du dort einen bestimmten "Score" erreichen musst. Der Bot reserviert für deine Website eine bestimmte Zeitspanne, sagen wir einmal 10 Sekunden. Braucht das Ausliefern jeder einzelnen URL schon 2 Sekunden, schafft der Bot in den 10 Sekunden gerade einmal 5 URLs.
Werden deine Seiten aber in 200 Millisekunden ausgeliefert, schafft der Bot in den 10 Sekunden die 10-fache Menge, nämlich 5 pro Sekunde und somit 50 URLs.
Bei kleineren Websites bis. 100.000 URLs muss man sich in der Regel um das Crawl-Budget keine Gedanken machen. Erst ab 100.000 URLs sollte man sich genau überlegen, welche Seiten der Bot crawlen soll.
Crawling einzelner Seiten oder Verzeichnisse verbieten
Grundsätzlich crawlt der Bot einer Suchmaschine alle Seiten und Dateien auf deinem Webserver, außer du verbietest es ihm. Dazu hast du mehrere Möglichkeiten:
URLs oder Verzeichnisse in die “robots.txt”-Datei eintragen. Mit dieser Datei zur Crawl-Steuerung verbietest du einem Bot, einzelne Seiten oder Seiten in einem Verzeichnis zu crawlen.
URLs oder Verzeichnisse mit einem Passwort schützen.
Dem Bot beim Crawlen einer Seite oder eines Verzeichnisses den Status-Code “403 Forbidden” zu liefern.
Ein “Meta noindex-Tag” in einer Seite verhindert nicht das Crawling, sondern nur die Indexierung. Ebenso wenig verhindert ein Eintrag einer Seite oder eines Verzeichnisses in die robots.txt die Indexierung, sondern nur das Crawling!
Selbst wenn das Crawling verboten ist, kann eine Seite aufgrund eines oder mehrerer interner Links im Index und somit in den Suchergebnissen landen.
Falls du deine Website über Cloudflare auslieferst, siehst du unter “Analytics und Protokolle” unter “Bedrohungen”, welche Crawler deine Website regelmäßig besuchen:

Bots, die deine Website regelmäßig besuchen auf Cloudflare
Im obigen Screenshot siehst du etwa den Eintrag "AppleBot". Das ist der Bot, den Apple für Suchanfragen auf deinen Apple-Geräten via Siri verwendet.
Bei Google findest du ein Support-Dokument, in dem die User-Agents aller GoogleBot aufgeführt sind. Auch bei Bing gibt es so eine Liste der User-Agents aller BingBots und natürlich hat auch Yandex eine Liste der User-Agents aller YandexBots veröffentlicht.
Nachdem eine Suchmaschine deine Seiten gecrawlt hat, werden sie möglicherweise indexiert.
Indexierung
Eine Seite wird nicht unbedingt indexiert, nur weil sie gecrawlt wurde. Suchmaschinen versuchen, nützliche Seiten und Inhalte zu erkennen und nur diese zu indexieren.
Früher haben Suchmaschinen vor der Indexierung einfach Stoppwörter wie Präpositionen, Artikel oder Konjunktionen aus einem Dokument entfernt. Dann wurden die verbleibenden Wörter auf Ihre Stammformen reduziert. Unter diesen Wörtern wurde dann eine Seite in einem invertierten Index gespeichert.
Heute verwendet eine Suchmaschine keinen reinen Wortindex mehr. Moderne Suchmaschinen sind semantisch und indexieren Seiten aufgrund ihrer inhaltlichen Bedeutung.
Früher musste ich etwa das Wort "photo spots rhyolite" häufig in einem Blogbeitrag über die Geisterstadt "Rhyolite" verwenden, damit die Seite für die Suchanfrage rankt. Bei der semantischen Suche ist es egal, ob ich im Text "photo spots rhyolite", "photo location rhyolite" oder "place to photograph" verwende. Bei einer semantischen Indexierung versteht eine Suchmaschine, dass es bei den drei Keywords inhaltlich um dasselbe geht.
Diese semantische Indexierung basiert auf sogenannten "Vektoreinbettungen". Damit wird der Inhalt einer Seite als mathematischer Vektor abgebildet. Sehr vereinfacht dargestellt, bekommt also ein Text über die besten Fotospots in der Geisterstadt Rhyolite einen Vektor wie in dieser schematischen Darstellung.
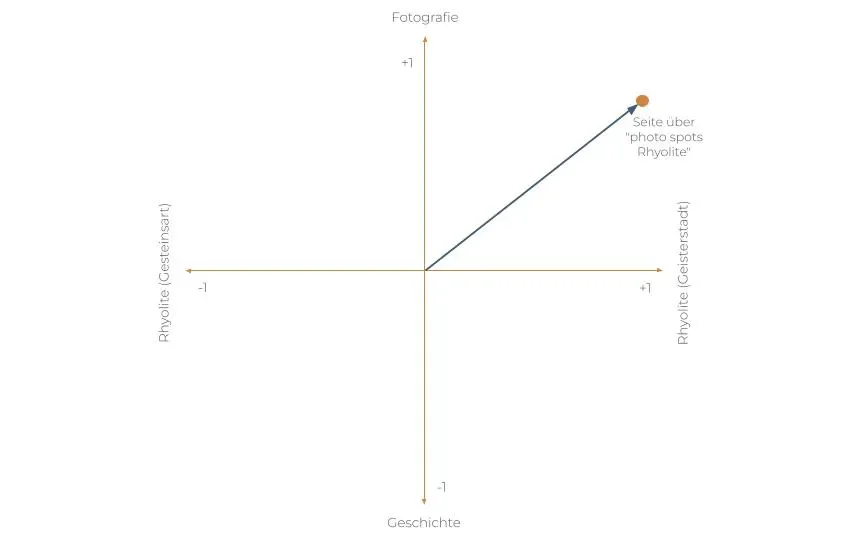
Vereinfachtes Beispiel einer Vektoreinbettung
In der Praxis hat ein Vektor für eine Seite allerdings nicht 2 Dimensionen wie im obigen Bild, sondern 1000 oder mehr Dimensionen.
In einem eigenen Blogbeitrag findest du eine verständliche Erklärung über Vektoreinbettungen und die Suchmaschinenoptimierung.
Damit deine Seite für das richtige Thema indexiert wird, geht es also nicht mehr darum, ein Keyword mit einer bestimmten Häufigkeit in einen Text zu stopfen. Vielmehr muss eine semantische Suchmaschine verstehen, worum es inhaltlich in deinem Text geht. So kannst du einer Suchmaschine dabei helfen:
Nenne die Dinge, über die du schreibst, beim Namen. Das sind Entitäten. Mehr dazu findest du in meinem Blogbeitrag über Entitäten für SEO verstehen und verwenden.
Verwende Entitäten vorwiegend in Hauptsätzen und in Nebensätzen eine ergänzende Beschreibung.
Bleib beim Thema. Schreibe ich einen Text über die Fotospots in der Geisterstadt Rhyolite, geht es darin nur um das Fotografieren. Es geht nicht um die Geschichte oder auch nicht um die geführte Tour dorthin. Die kannst du gerne in einem oder 2 Sätzen erwähnen, aber im Hauptteil des Textes geht es um das Fotografieren.
Indexierung einzelner Seiten verbieten
Natürlich kannst du eine Suchmaschine anweisen, bestimmte Seiten nicht zu indexieren. Dazu hast du im Wesentlichen 3 Möglichkeiten:
Füge das “noindex-Meta-Tag” im HEAD-Bereich der Seite hinzu, die nicht indexiert werden soll.
Konfiguriere deinen Server so, dass du im HTTP Header das Feld “X-Robots-Tag: noindex” an den Bot lieferst.
Schütze die Seite mit einem Passwort.
Hat Google eine Seite bereits indexiert und du möchtest sie aus dem Index entfernen, gehe bitte so vor:
Verwende eine der vorhin genannten Methoden, etwa das “noindex-Meta-Tag”.
Verwende das URL Removal-Tool in der Search Console, um die Anzeige der Seite in den SERPs sofort zu unterbinden.
Dadurch wird die Seite zunächst nicht mehr in den Suchergebnissen angezeigt und beim erneuten Crawling wird der Bot erkennen, dass die Seite nicht indexiert werden soll und sie aus dem Index entfernen.
Blockierst du das Crawling einer Seite, die ein noindex-Meta-Tag enthält, durch die robots.txt-Datei, kann Google die Seite nicht crawlen und sieht damit das noindex-Meta-Tag nicht. Dadurch bleibt die Seite indexiert!
Ranking
Seit den Google Leaks wissen wir, dass das Ranking einer Suchmaschine wie Google ein mehrstufiger Prozess ist.
Query Expansion
Eine Suchmaschine verwendet eine Suchanfrage nicht unbedingt so, wie Menschen sie im Suchfeld eingegeben haben.
Sie kann die eingegebene Suchanfrage ändern. Das wird als “Query Expansion” bezeichnet. Hier ein ganz einfaches Beispiel: Gibst du als Suchanfrage den Begriff “Rhyolite” ein, weiß eine Suchmaschine zunächst nicht, ob du nach Seiten über die Gesteinsart “Rhyolith” (engl. “Rhyolite”) suchst oder über Informationen zur gleichnamigen Geisterstadt in Nevada.
Basierend auf deiner Suchhistorie oder allgemeinen Engagement-Signalen (wie etwa Klicks) mit den Suchergebnissen erweitert eine Suchmaschine die Suchanfrage “Rhyolite” beispielsweise um das Wort “Nevada”. Damit behandelt eine Suchmaschine die Suchanfrage nach “Rhyolite” so, also ob du nach “Rhyolite Nevada” gesucht hättest und zeigt dir Suchergebnisse über die Geisterstadt an.
Ob und wie eine Suchmaschine “Query Expansion” betreibt, bekommen Nutzerinnen der Suchmaschine in der Regel nicht mit. Die veränderte Suchanfrage wird nicht angezeigt.
Initial Ranking
In einem Protokoll zum Google Hearing vor dem DOJ aus dem Jahr 2023 (Seite 6.400) erwähnt Google das “initial Ranking”. In diesem ersten Ranking wird ein Pool von inhaltlich relevanten Seiten aus dem Index ermittelt. Laut Google können das bis zu 10.000.000 Seiten sein. Andere Quellen sprechen in diesem ersten Ranking-Schritt lediglich von ein paar Tausend Seiten.
Laut dem Protokoll bezeichnet Google diesen Pool als den “Green Ring” (Seite 6.403). In diesem Schritt ermittelt Google thematisch relevante Seiten in Relation zu einer Suchanfrage. Dabei wird für die Suchanfrage nach der Query Expansion mittels Vektoreinbettung ein Vektor ermittelt, der mit dem Index abgeglichen wird. Dadurch werden im ersten Schritt thematisch relevante Seiten ermittelt.
Wir wissen allerdings nicht, welche Ranking-Signale sich abseits der thematischen Relevanz zusätzlich auf das erste Ranking auswirken. Meine Hypothese ist, dass dabei bestimmte Qualitäts-Signale (wie etwa, ob eine Seite als SPAM klassifiziert ist) zum Einsatz kommen.
Re-Ranking
Die Ergebnisse aus dem ersten Schritt (dem "Green Ring") werden nun einem Re-Ranking unterzogen. Dabei wird einerseits die Anzahl der Ergebnisse auf einige hundert reduziert. Andererseits kann sich auch die Reihenfolge der Suchergebnisse ändern.
Laut dem DOJ Dokument bezeichnet Google das geänderte Ergebnis des Re-Rankings als “Blue Ring” (Seite 6.403). Das sind dann die Suchergebnisse, die in den Suchergebnissenangezeigt werden.
Beim Re-Ranking kommen spezialisierte Ranking-Systeme zum Einsatz. Einige werten eine Seite leicht auf oder ab, andere (wie das 'Navboost'-System) beziehen starke Nutzersignale mit ein.
Ranking-Signale und Ranking-Systeme
Es gibt keine offizielle Liste aller Ranking-Signale. Sämtliche Listen dazu sind Vermutungen beziehungsweise Hypothesen, von denen einige sicherlich korrekt waren. Achte bitte auf meine Wortwahl: Ich schreibe bewusst "Ranking-Signale" statt "Ranking-Faktoren". Der Begriff "Ranking-Faktoren" lässt noch immer Menschen glauben, dass sie eine Checkliste für SEO abarbeiten müssen. Das ist nicht der Fall.
Ranking-Signale haben unterschiedliche Gewichtungen. So kann ein Ranking-Signal eines Ranking-Systems eine Seite um 10 Plätze nach unten ranken. Ein anderes Signal im Re-Ranking kann dann eine Seite wieder um 5 Plätze nach oben bringen. Schließlich sind Ranking-Signale gewichtet und wirken sich somit unterschiedlich stark auf das Ranking aus.
Die für die Ranking-Signale sind Ranking-Systeme verantwortlich. Es gibt dafür eine vollständig bestätigte Liste. Google hat lediglich eine nicht vollständige Liste mit einigen Ranking-Systemen veröffentlicht.
Ein Beispiel für solche Ranking-Signale sind die Core Web Vitals (“Page Speed”). Die sind natürlich ein Ranking-Signal, sind aber nicht so stark gewichtet wie inhaltliche Relevanz-Signale. Eine Suchmaschine wird eine langsame, aber relevante Seite stets weiter oben ranken als eine schnelle, aber inhaltlich weniger relevante Seite.
Das "Re-Ranking" ist auch der Grund, warum ein Mitbewerb für etwas (z.B. viel Werbung) anscheinend nicht so heftig “abgestraft” wird, wie deine Website. Während deine Website und die eines Mitbewerbs durch ein Ranking-Signal gleich stark abgestraft werden, wird die Seite deines Mitbewerbs durch andere Ranking-Signale wieder stärker nach oben gereiht als deine.
Laut einem Artikel auf Search Engine Land über den Yandex Leak (2023) wurden bei einem Yandex-Leak insgesamt 1.922 Ranking-Signale entdeckt. Beim Google-Leak im Jahr 2024 wurden je nach Quelle bis zu 14.000 Ranking-Signale gefunden.
Ich würde SEO daher nicht auf eine (veraltete) Liste von “200 Ranking Signalen” oder Aussagen wie “Eine H1” stützen. Mache dich stattdessen mit wichtigen Konzepten rund um das Ranking vertraut:
Die Säulen der semantischen Suche im Allgemeinen.
Die 3 Ebenen der Suchintention.
Was EEAT für SEO bedeutet.
Diese Themen behandle ich auch in meinem Kurs zur strukturierten Keyword-Recherche auf Udemy.
Serving
Nachdem eine Suchmaschine die Suchergebnisse ermittelt hat, werden sie ausgeliefert. Das wird als "Serving" bezeichnet. Eine Suchergebnisseite wird als "Search Engine Results Page" (Abk. "SERP") bezeichnet. Sie besteht aus mehr als nur aus 10 Weblinks. Zusätzlich kann sie verschiedene Module enthalten, wie etwa:
Werbeanzeigen
Eine KI-Übersicht
Bilder
Videos
Map-Pack
Nachrichten
Die Inhalte dieser Elemente werden parallel zu den 10 blauen Links ermittelt und vor dem Serving des Suchergebnisses dort eingebaut. Das bezeichnet Google als “Universal Search”, wie du im Google Blog nachlesen kannst.
Beim Serving kommen finale Systeme zum Einsatz, die all diese Module (klassische Suchergebnisse, Videos, KI-Antwort) zu einer einzigen Ergebnisseite zusammenführen. Laut einem DOJ-Hearing-Protkoll sind zwei Beispiele dafür die Systeme “Glue” und “Tetris” (DOJ Hearing Protokoll 2023, Seite 6403).
Die Suche verwendet schon seit langem KI
Google verwendet schon seit 2012 KI-Systeme für das Ranking. Der Startzeitpunkt dafür war fließend. Einerseits gehört die Nutzung von Entitäten (2012) dazu und andererseits das Hummingbird-Update (2013).
Viele Tipps, die du jetzt für das "neue" GEO/LLMO liest, sind schon seit damals wichtig und nicht wirklich neu.
Zusammenfassung
Damit deine Seiten in den Suchergebnissen angezeigt werden, kann jede Seite 4 Schritte durchlaufen.
Zunächst muss eine Suchmaschine aber wissen, dass deine Website überhaupt existiert. Danach muss sie gecrawlt und indexiert werden.
Das Ranking ist kein trivialer Prozess (mehr), der alleine mit Algorithmen aus den 70er und 80er Jahren wie TDF/IDF oder BM25 funktioniert. Er besteht bei modernen Suchmaschinen aus mehreren Schritten, bei denen viele Ranking-Systeme beteiligt sind, die ein (z.B. “Twiddler”) oder mehrere Ranking-Signale (z.B. “Navboost” oder “Freshness”) berücksichtigen.
Meine Empfehlung ist daher, dich nicht mehr mit alten “Ranking-Faktoren-Listen“ zu beschäftigen, sondern die wichtigen Konzepte einer semantischen Suchmaschine und des Information-Retrieval zu verstehen. Dazu gehören die Säulen der semantischen Suche, die 3 Ebenen der Suchintention und was EEAT für SEO bedeutet.
Diese Punkte beeinflussen auch, wie, ob und wo deine Seiten in den SERPs beim "Serving" angezeigt werden.